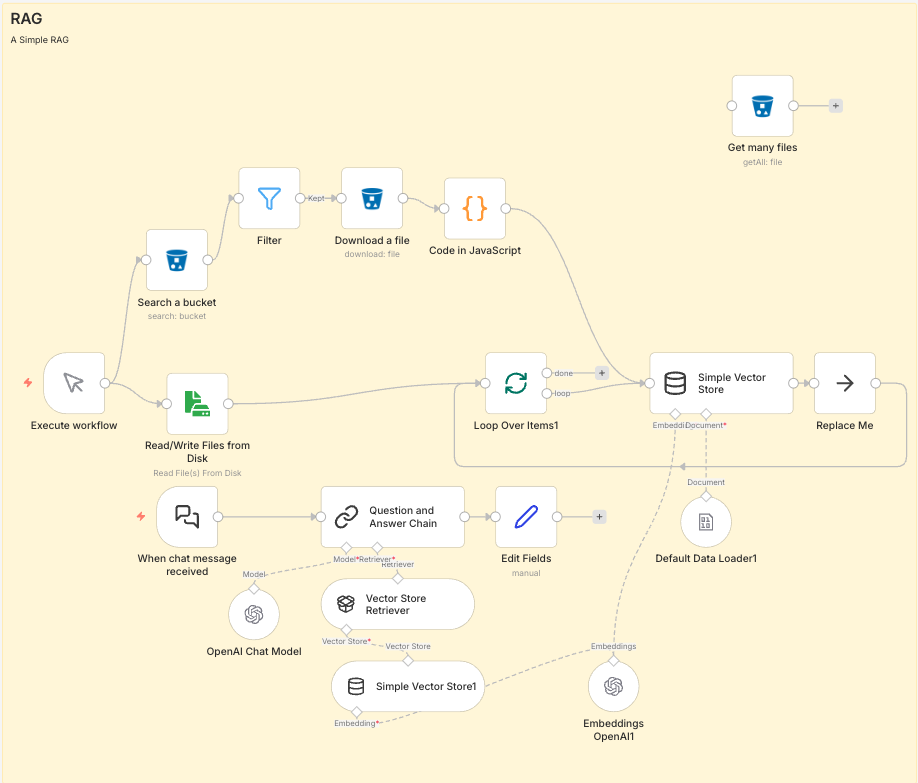
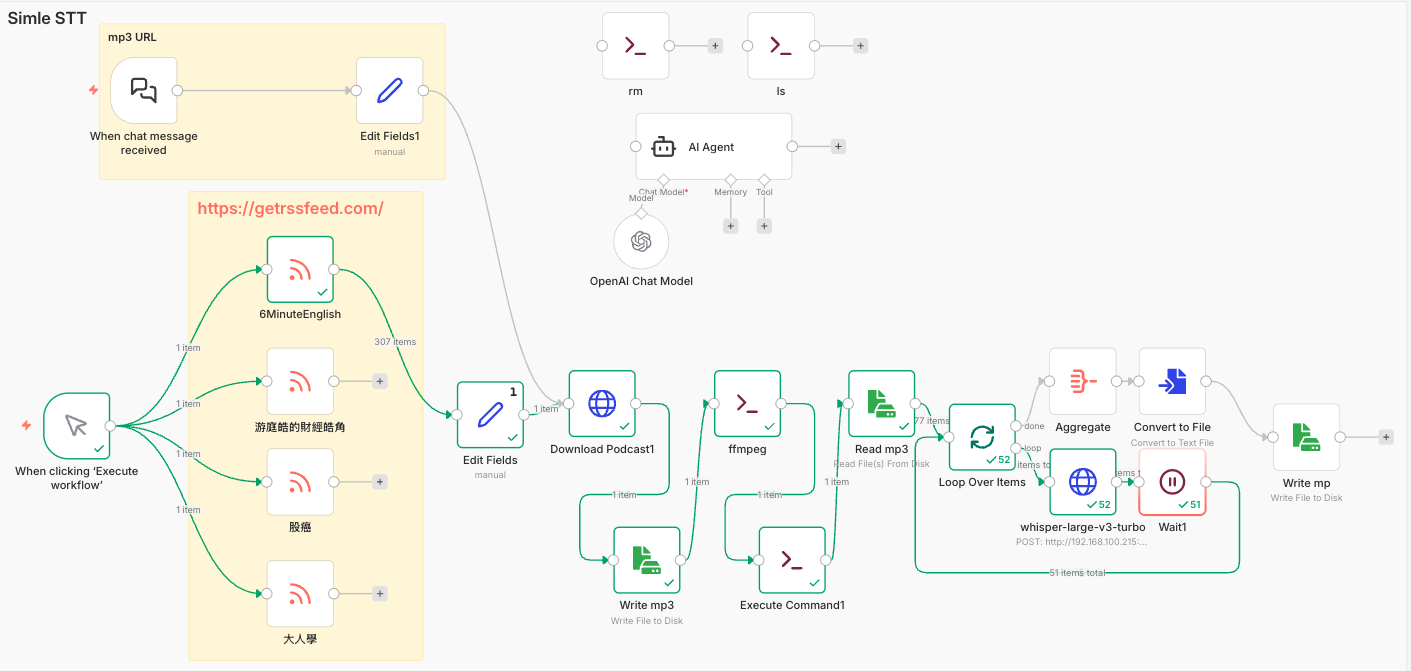
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
$ sudo docker pull intel/llm-scaler-vllm:1.2
$ sudo docker run -td \
--privileged \
--net=host \
--device=/dev/dri \
--name=llm-container \
-v ../models/:/llm/models/ \
-e no_proxy=localhost,127.0.0.1 \
-e http_proxy=$http_proxy \
-e https_proxy=$https_proxy \
-p 8000:8000 \
--shm-size="8g" \
--entrypoint /bin/bash \
intel/llm-scaler-vllm:1.2
$ sudo docker restart llm-container
$ sudo docker exec -it llm-container bash
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 \
VLLM_WORKER_MULTIPROC_METHOD=spawn \
python3 -m vllm.entrypoints.openai.api_server \
--model /llm/models/gpt-oss-20b \
--served-model-name gpt-oss-20b \
--dtype=bfloat16 \
--enforce-eager \
--port 8000 \
--host 0.0.0.0 \
--trust-remote-code \
--gpu-memory-util=0.7 \
--no-enable-prefix-caching \
--max-num-batched-tokens=2048 \
--disable-log-requests \
--max-model-len=4096 \
--block-size 64 \
--api-key 1234 \
-tp=1
# 占用 13.3 GB
# 測試
$ curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer 1234" \
-d '{
"model": "gpt-oss-20b",
"messages": [{"role": "user", "content": "簡短自我介紹。"}]
}'
|